

Modern DevOps is all about delivering high-quality features in a safe and fast way. So far, I am using a single pipeline for all of my CI/CD. This works fine but also makes it harder to make changes in the future. In software development, we have the Single Responsibility Principle (SRP) which states that a class or method should only do one thing. This makes the code simpler and easier to understand. The same principle can be applied to the CI/CD pipeline.
This post shows how to split up the existing CI/CD pipeline into a CI and a CD pipeline. The separation will make the pipelines simpler and therefore will promote the ability to make changes quickly in the future.
This post is part of “Microservice Series - From Zero to Hero”.
Things to consider before splitting up the CI/CD Pipeline
You can find the code of the demo on GitHub.
Splitting up the pipeline into a separate CI and CD pipeline is quite simple and barely needs any changes. If you are new to this series, check out Improve Azure DevOps YAML Pipelines with Templates first and read about the templates used in the CI/CD pipeline.
The only thing you have to consider before splitting up the CI/CD pipeline is how the CD pipeline knows that it should run and how it can access files from the CI pipeline.
Edit the Pipeline for Continuous Integration
Continuous Integration or CI means that you want to integrate new features always into the master branch and have the branch in a deployable state. This means that I have to calculate the build version number, build the Docker image, push it to Docker Hub and create the Helm package which will be used in the CD pipeline for the deployment. All this exists already and the only step I have to add is publishing the values.yaml file and the Helm package to the ArtifactStagingDirectory. This is a built-in variable of Azure DevOps and allows the CD pipeline to access the Helm package and the config file during the deployment.
The changes are made in the CreateHelmPackage template. The whole template looks as follows:
Splitting up the CI and CD part also helps to make the pipeline smaller. For example, only around half of the variables are needed for the CI pipeline. The whole CI pipeline looks as follows:
Creating the Continuous Deployment Pipeline
The Continuous Deployment (CD) pipeline might look a bit complicated at first, but it is almost the same as it was before. The first step is to create a new file, called CustomerApi-CD in the pipelines folder and then configure a trigger to run the pipeline after the CI pipeline. This can be achieved with the pipelines section at the top of the pipeline.
This code references the CustomerApi-CI which is the name of the CI pipeline and runs when there are changes on the master branch or if a pull request triggered the CI pipeline. Next, change the path to the Helm chart package and the values.yaml file. These files were uploaded by the CI pipeline and can be found in the Pipeline.Workspace now. This is a built-in variable of Azure DevOps and allows you to access files uploaded by the CI pipeline. The path to the files looks as follows:
The next step is to download the Helm package and the database. This section stays almost the same, except that you have to download the Helm package from the CI pipeline. This is done with the following code.
The finished CD Pipeline
The finished CD pipeline looks as follows.
Test the new CI and CD Pipelines
Before you can use the new CD pipeline, add it to your Azure DevOps pipelines. To do that, open the Pipelines in your Azure DevOps project, click New pipeline and then select the location where your code is stored. On the next page, select Existing Azure Pipelines YAML file and then select the path to the new CD pipeline from the drop-down menu.
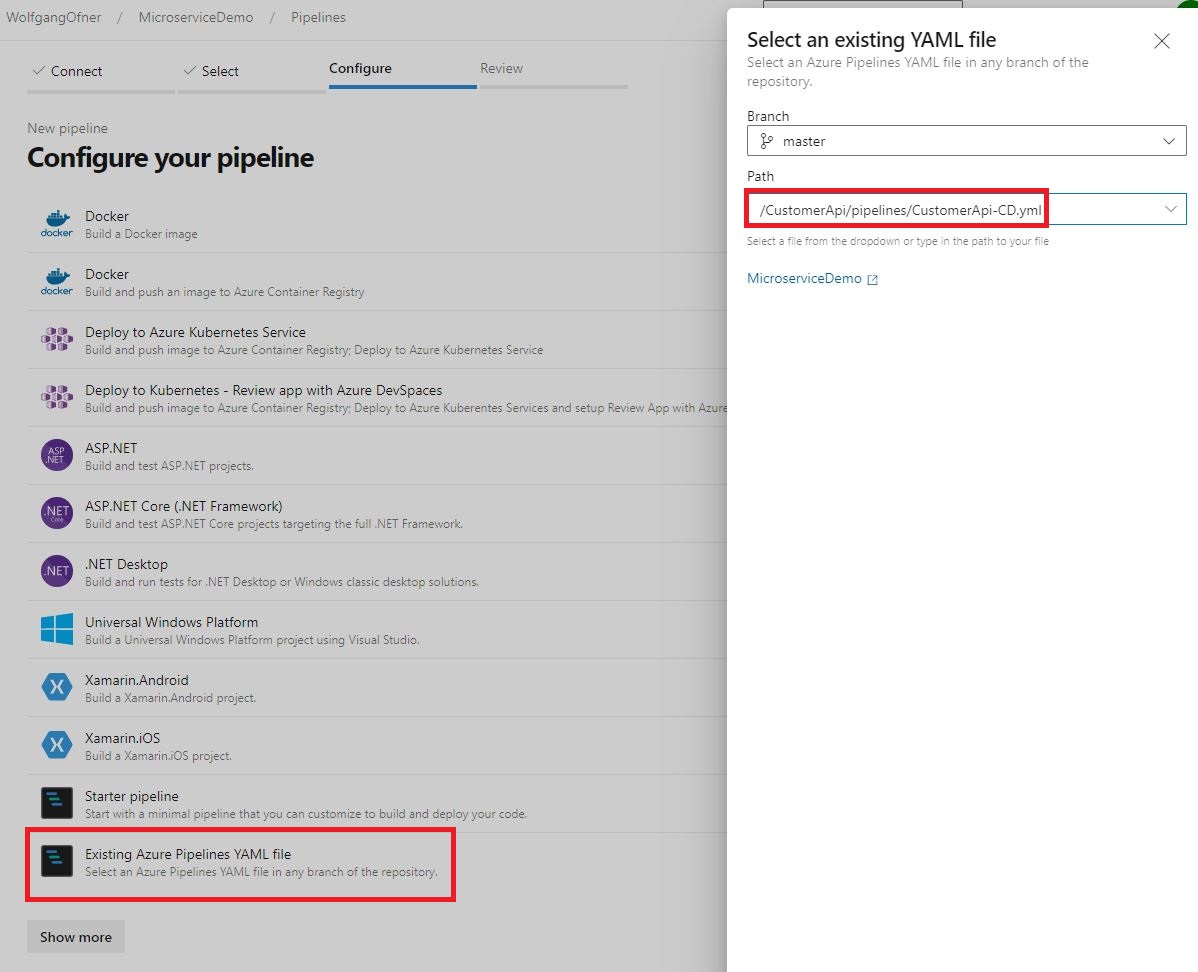
Add the new CD Pipeline to Azure DevOps
If you used any secret variables, for example, for the database password, do not forget to add them to the new CD pipeline before you start the deployment.
Run the CI pipeline and after the build is finished, the CD pipeline will kick off and deploy the application. After the deployment is finished, open your browser and enter your URL (configured in the URL variable in the CD pipeline) and you should see the Swagger UI of the microservice.
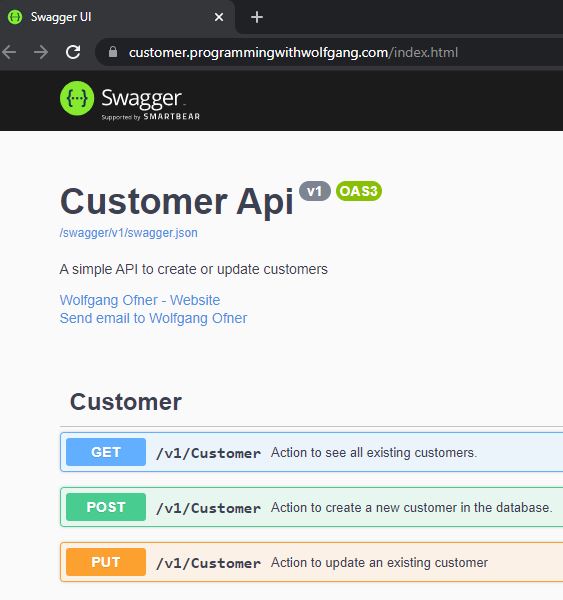
The Microservice is running
To access the microservice using the URL, you have to configure the DNS accordingly. See Configure custom URLs to access Microservices running in Kubernetes to learn how to do that using an Nginx ingress controller.
Conclusion
Using two pipelines, one for CI, and one for CD can be achieved quite easily and helps you to keep the complexity inside the pipelines at a minimum. This allows you to add new features, for example, new environments fast and with a smaller chance of making any mistakes.
In my next post, I will use the newly created CD pipeline and add a production stage with its own URL and database deployment.
You can find the code of the demo on GitHub.
This post is part of “Microservice Series - From Zero to Hero”.
Comments powered by Disqus.