

I showed in my last post how to automatically deploy database changes to your database. In this post, I will extend my microservice to use this database and also extend the deployment to provide a valid connection string.
This post is part of “Microservice Series - From Zero to Hero”.
Update the Microservice to use a Database
You can find the code of the demo on GitHub.
So far, the microservice uses an in-memory database. I want to keep the option to use the in-memory database for local debugging. Therefore, I add the following value to the appsettings.Development.json file:
If you want to run the microservice locally with a normal database, set this value to false. Next, I add the database connection string to the appsettings.json file:
It is a best practice to use User Scripts when you are dealing with sensitive data in your local environment. To add User Secrets, right-click on your project and select Manage User Scripts.

Add User Secrets
After adding the settings, we only need one more change in the Startup.cs class. Here we change the configuration of the in-memory database to either configure a real database connection or the in-memory one, depending on the settings:
To use an SQL Server, you have to install the Microsoft.EntityFrameworkCore.SqlServer NuGet package.

Install the SQL Server NuGet package
Additionally, comment out the code in the constructor of the CustomerContext. The data was used as initial values for the in-memory database.
If you want, run the application locally and test the database connection.
Pass the Connection String in the CI/CD Pipeline
Providing the connection string in the CI/CD pipeline is simpler than you might think. All you have to do is add the following code to the values.yaml file inside the Helm chart folder of the API solution.
This code sets the connection string as a secret in Kubernetes. Since the hierarchy is the same as in the appsettings.json file, Kubernetes can pass it to the microservice. The only difference is that the json file uses braces for hierarchy whereas secrets use double underscores (__). The value for __ConnectionString__ will be provided by the ConnectionString variable during the tokenizer step in the pipeline.
Test the Microservice with the database
Deploy the microservice and then open the Swagger UI. Execute the POST operation and create a new customer.

Add a new customer to the database
Connect to the database, for example, using the SQL Management Studio and you should see the new customer there.
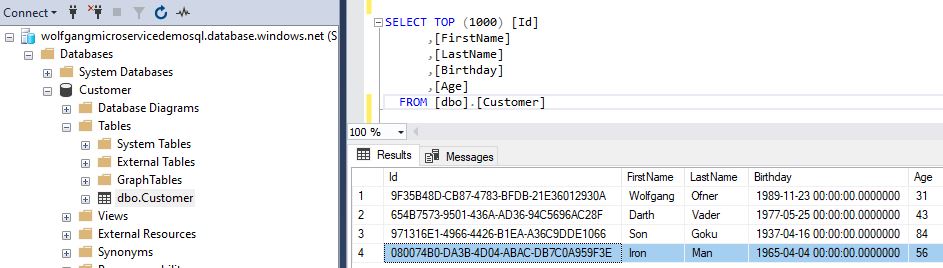
The new customer was added to the database
Conclusion
Using a database with your microservice works the same way as with all .NET 5 applications. Due to the already existing CI/CD pipeline which is using Helm to create the deployment package, there were barely any changes necessary to pass the connection string to the microservice during the deployment.
You can find the code of the demo on GitHub.
This post is part of “Microservice Series - From Zero to Hero”.
Comments powered by Disqus.